
Warning
Scalability tests reported below have been run with an old AMITEX_FFTP version and an old HPC machine
Main conclusions are not expected to be modified with more recent versions
The following scalability performances have been evaluated with the 1.0.1 version and the poincare IBM cluster available at Maison de la Simulation which consists of 92 nodes with 2 processors Sandy Bridge E5-2670 and 32Go of RAM per node.
All the simulations have been performed with default algorithm parameters (Basic Scheme + Convergence Acceleration procedure, Filtered discrete Green operator with the hexaedral filter).
Scalability tests are evaluated from 16 to 1024 cores (1 to 64 nodes).
As shown below, the scalability strongly depends on the numerical efficiency of the behavior law evaluation.
MAIN CONCLUSIONS:
Note that AMITEX_FFTP is rather developed to account for “heavy” behaviors, accounting for more and more complex physical mechanisms, than simple linear elasticity.
As shown on the figures below, all the unit-cells used for the following studies consist of periodic multiplications of a reference \(128^3\) unit-cell (polycrystal). The behavior is a cristalline behavior available within the Mfront library (see Installation).

|

|

|
| 1 cell (128^3) | 8 cells (256^3) | 64 cells (512^3) |
| Examples of unit-cells used for weak and/or strong scalability studies | ||
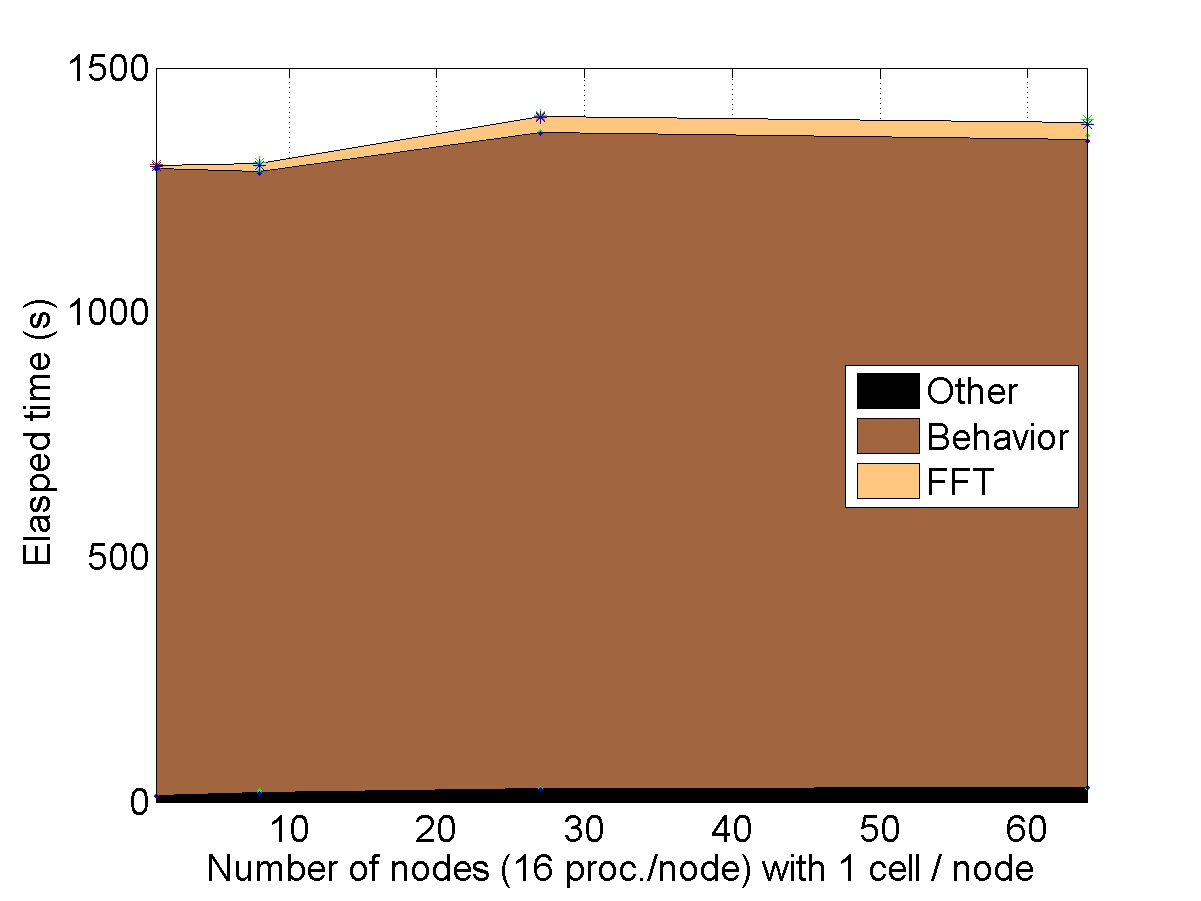
WEAK SCALABILITY: N cells on N nodes
The number of cells within the unit-cell is equal to the number of nodes used for the simulation.
CONCLUSION : with “heavy” behaviors, the AMITEX_FFTP parallel implementation is very efficient to increase the problem size (quasi-ideal weak scalability)
|
| N cells on N nodes |
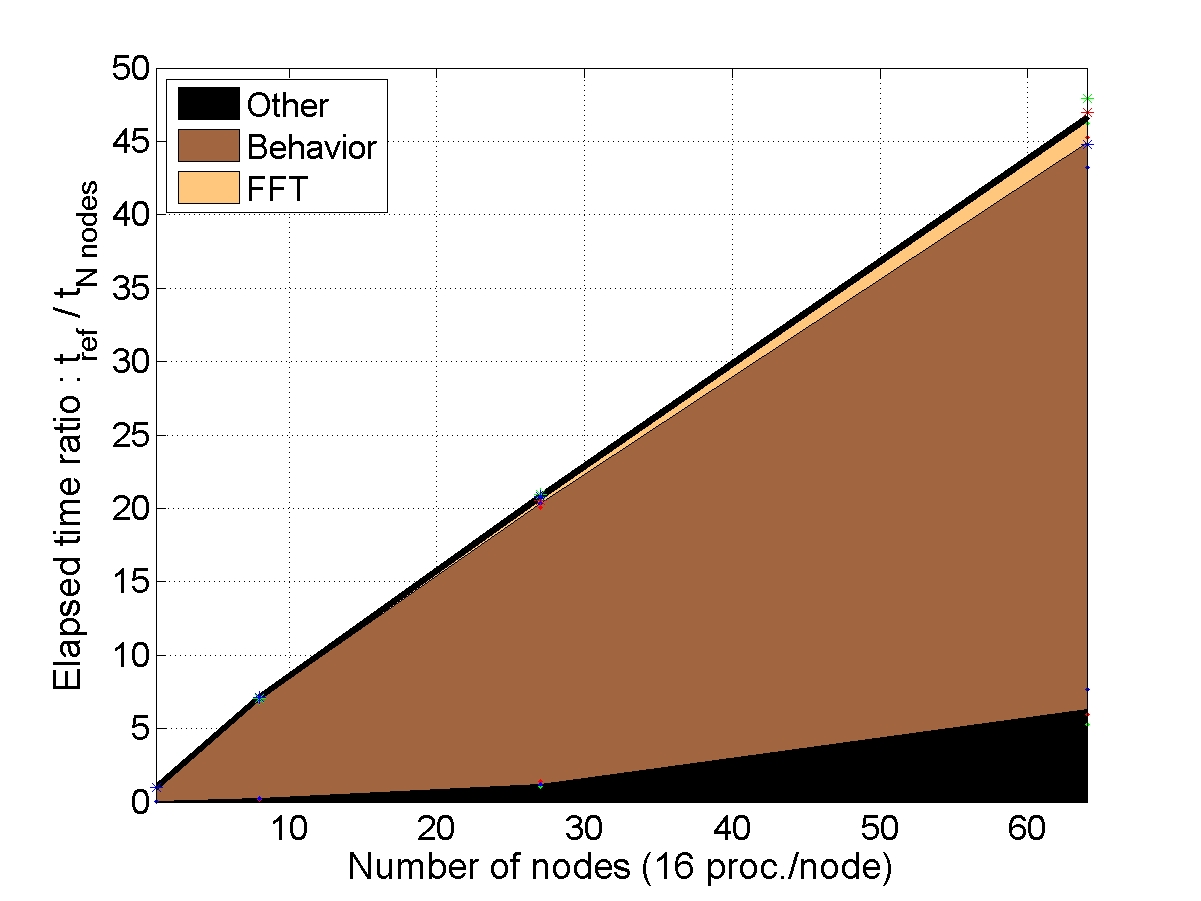
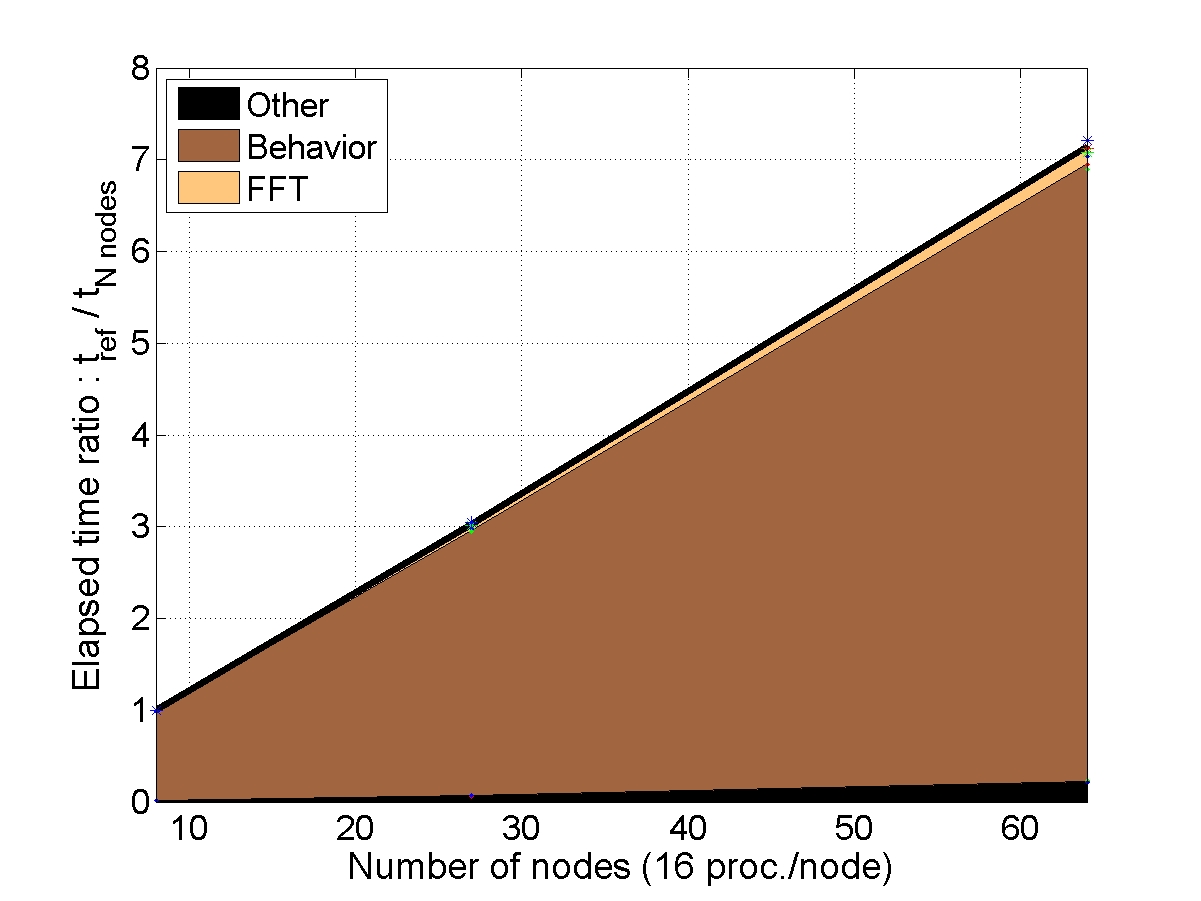
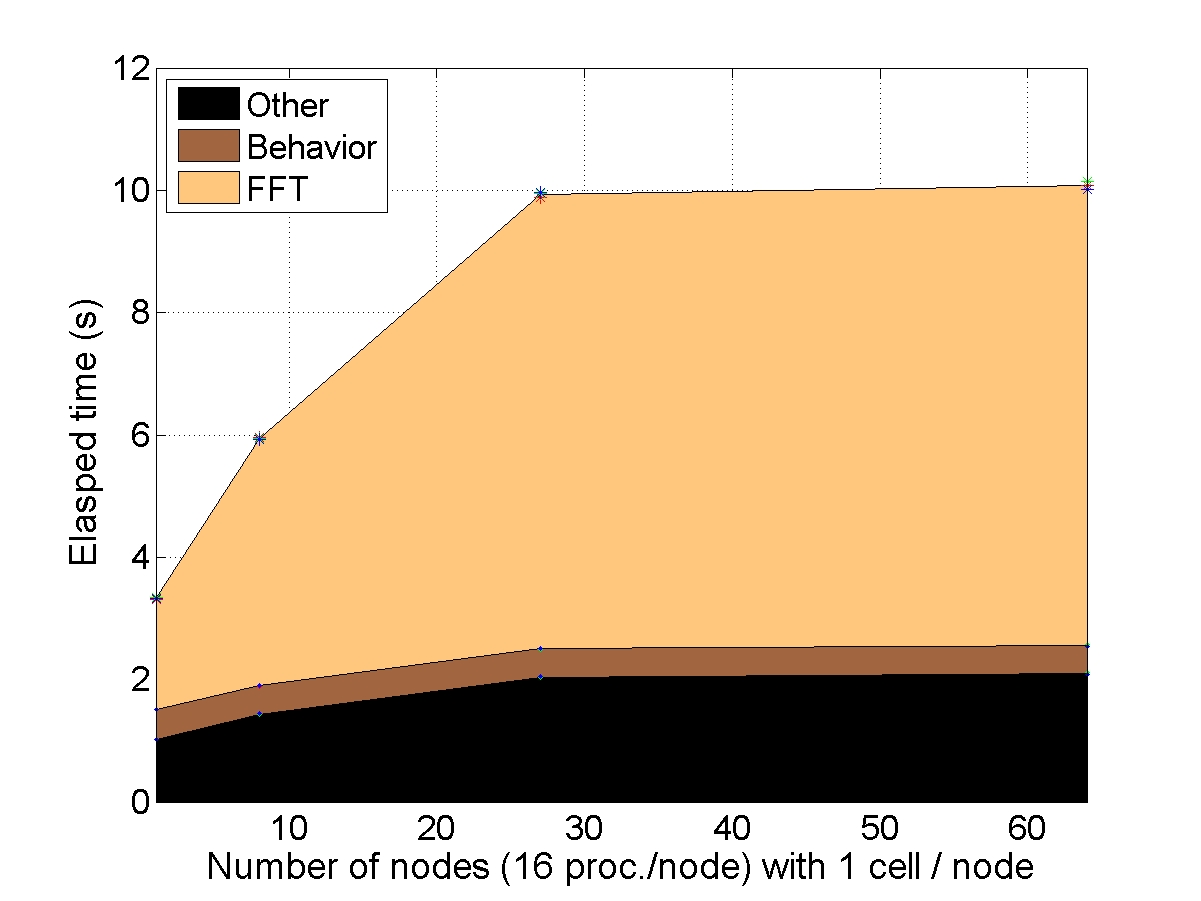
STRONG SCALABILITY: X cells on N nodes
The number of cells within the unit-cell is fixed (1 or 8) and the number of nodes used for the simulation increases. The elapsed time is compared to a reference elapsed time on 1 node (or 8 nodes for the bigger unit-cell).
CONCLUSION : with “heavy” behaviors, the AMITEX_FFTP parallel implementation is very efficient to decrease the elapsed time (very good strong scalability)
|
|
|
|
As shown on the figures below, all the unit-cells used for the following studies consist of periodic multiplications of a reference \(128^3\) unit-cell (polycrystal). Matrix is stiffer than inclusions with an elastic contrast of 100.

|

|

|

|
| 1 cell (128^3) | 8 cells (256^3) | 64 cells (512^3) | 512 cells (1024^3) |
| Examples of unit-cells used for weak and/or strong scalability studies | |||
WEAK SCALABILITY: NxX cells on N nodes
The number of cells within the unit-cell is proportional (x1 or x8) to the number of nodes used for the simulation.
CONCLUSION : with “light” behaviors, the AMITEX_FFTP parallel implementation can be used quite efficiently to increase the problem size (weak scalability)
|
|
| (Nx1) cells on N nodes | (Nx8) cells on N nodes |
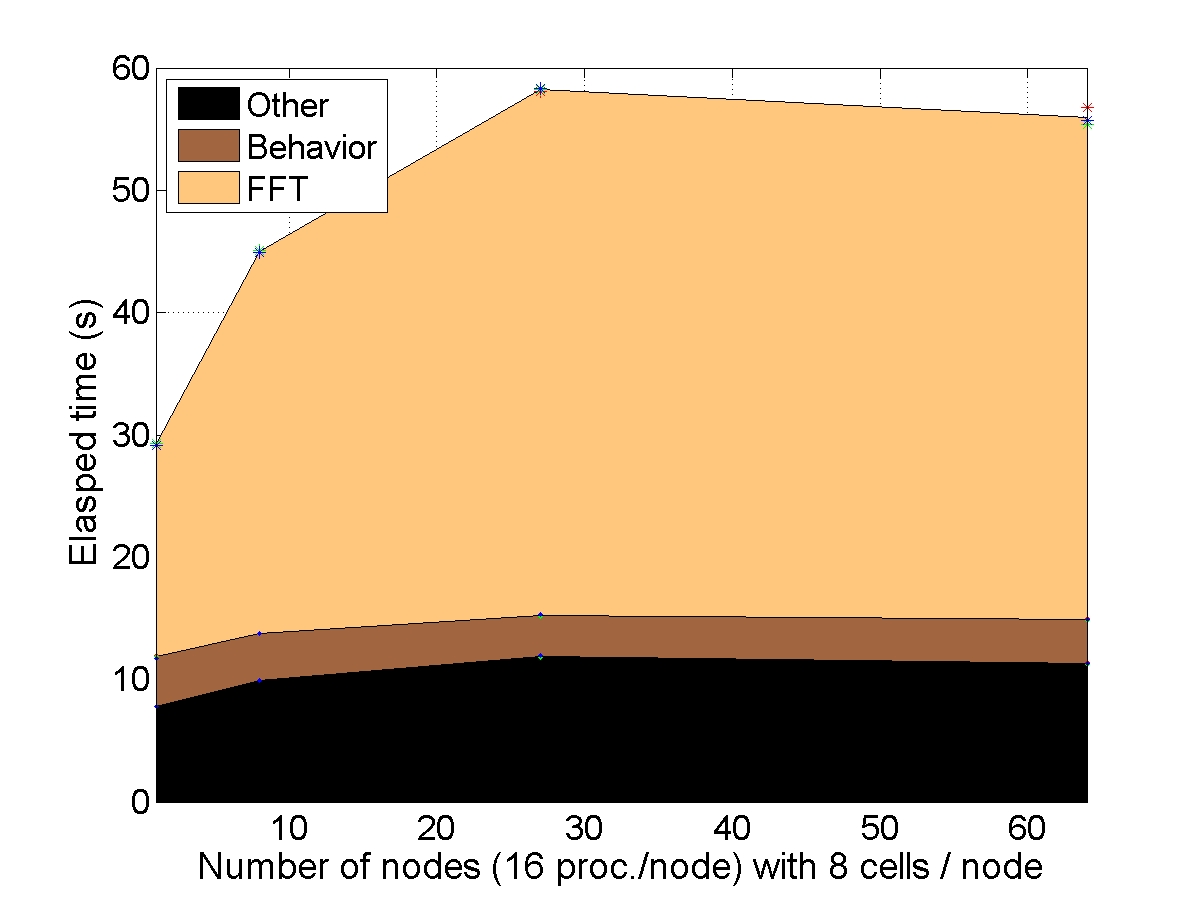
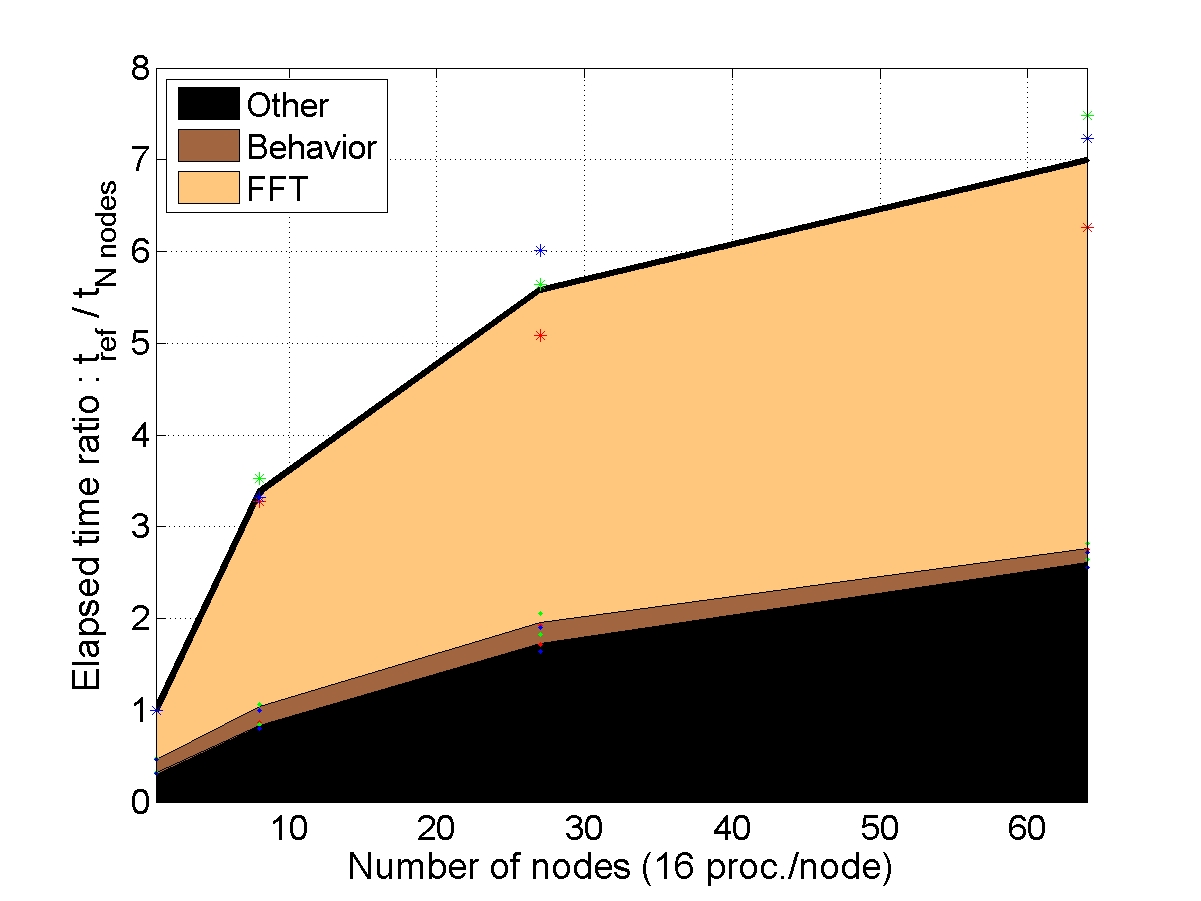
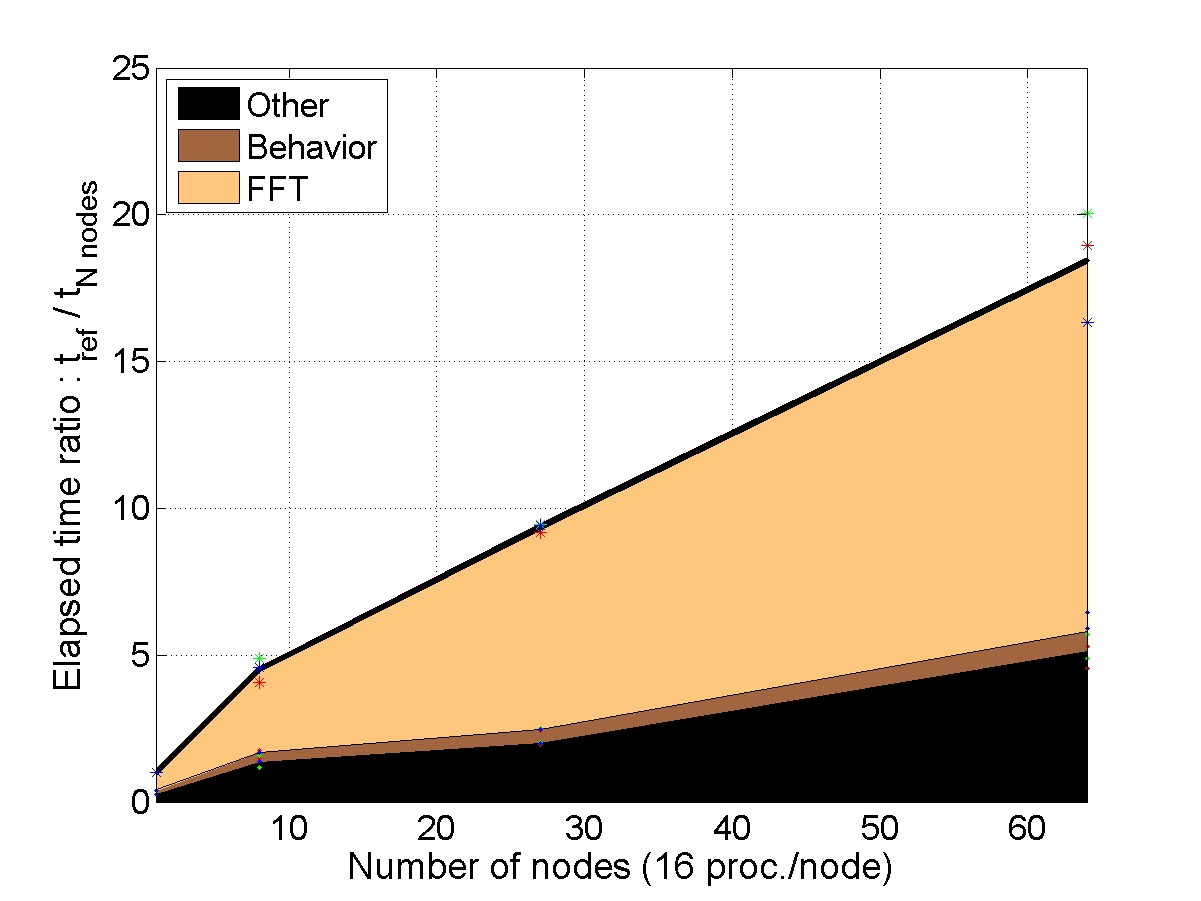
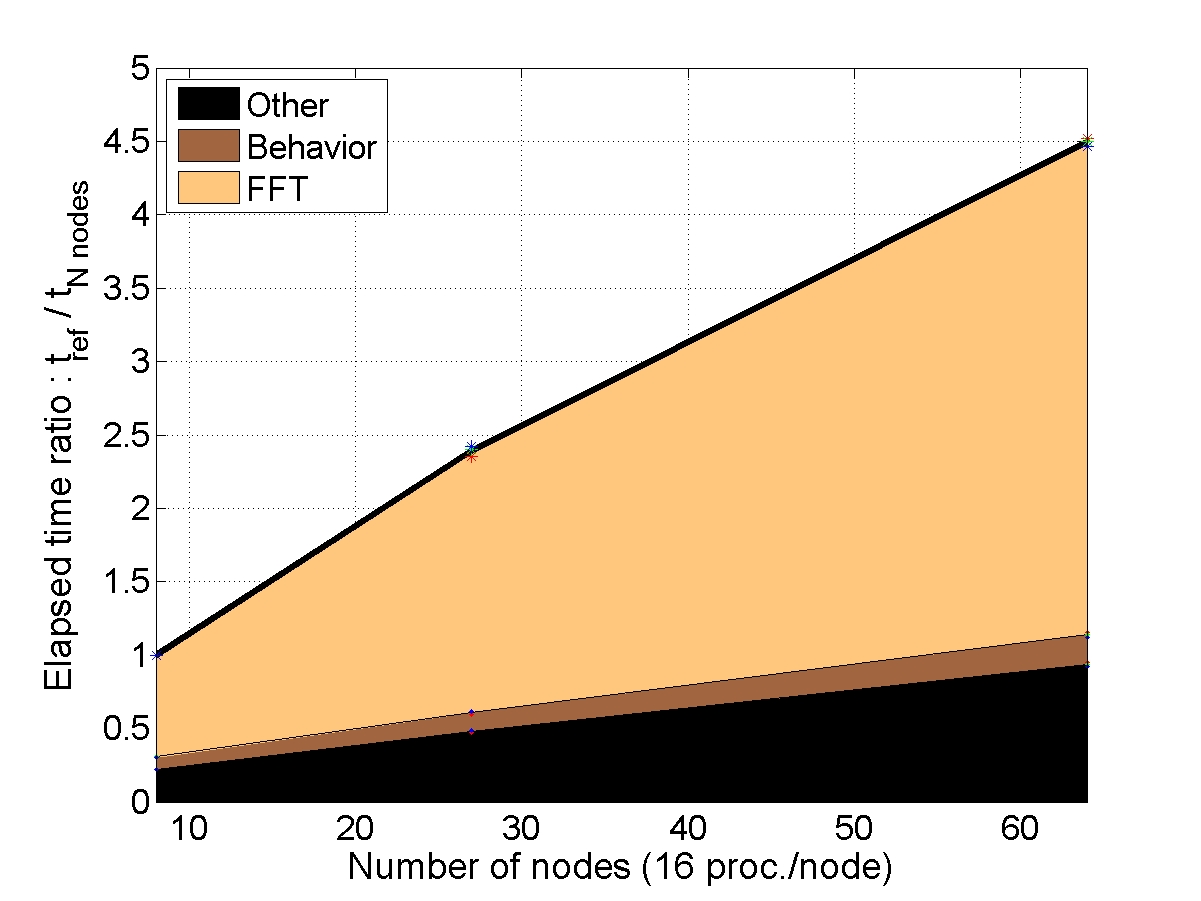
STRONG SCALABILITY: X cells on N nodes
The number of cells within the unit-cell is fixed (1, 8 or 64) and the number of nodes used for the simulation increases. The elapsed time is compared to a reference elapsed time on 1 (or 8 nodes for the bigger unit-cell).
CONCLUSION : with “light” behaviors, the AMITEX_FFTP parallel implementation is efficient to reduce the elapsed time if the problem size is large enough
|
|
|
|
|
|